
paper https://arxiv.org/pdf/1811.03233.pdf
글출처: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=hist0134&logNo=221525718843
네이버 콜로키움에 가서 정말 재미있게 들었던 허병호 님의 AAAI 2019 논문 (발표는 Clova AI의 윤상두 님) 입니다. 이 논문에서는 Knowledge Distillation 이라는 (이하 KD, 이전에 제 블로그에서도 FitNets 라는 논문으로 다룬 적이 있었던) 분야를 다루었습니다. KD 분야의 주 목적은 미리 학습시킨 teacher network 로부터 쓸만한 정보 (knowledge) 를 학습해, 청출어람을 꿈꾸는 student network를 잘~ 학습시키는 것입니다. 기존의 KD 연구들은 teacher network에서 활성화되는 값, 즉 activation (output prediction, attention weight, hidden representation 등) 자체를 따르도록 student network를 학습시키는 방법을 사용해왔습니다. 반면에 이 논문은 activation 자체가 아니라, teacher network의 activation boundary를 따르도록 학습해야 한다고 주장하고 있습니다. 여기서 말하는 "activation boundary를 따른다"라는 말의 의미는, teacher network에서 ReLU를 통과한 값이 0이라면 (deactivated) student network도 ReLU를 통과했을 때 0이어야 (deactivated) 하고, teacher network에서 ReLU를 통과한 값이 0보다 크다면 (activated) student network도 ReLU를 통과했을 때 0보다 커야 한다(activated)는 뜻입니다. 0보다 얼마나 커야할지, 얼마나 작아야할지에 대해서는 궁금해하지 않는다는 점에서 기존의 KD 연구들과 방향이 다르다고 할 수 있습니다.
왜 activation boundary를 가져와야 하는가? 를 논문에서 굉장히 잘 설명하고 있습니다. classification 문제에서 학습하는 것은 (feature space 에서의) decision boundary 입니다. 얼마나 좋은 decision boundary를 학습했느냐에 따라서 실제 classification 성능이 달라지게 됩니다. 일반적으로 "좋은 decision boundary"라고 함은, generalization이 잘 되어있어서 처음 보는 데이터에서도 제대로 동작할 수 있는 decision boundary를 좋은 decision boundary 라고 합니다. classification 문제에서 가장 중요하게 여기는 것이 바로 decision boundary 죠.
그리고 최근 연구 (Pan and Srikumar et al., 2016) 에서, 그 중요한 decision boundary가 곧 신경망 내부의 activation boundary의 조합으로 이루어져 있다고 밝혔습니다 (그렇다고 합니다). teacher가 학습한 중요한 knowledge라는 것은 결국 teacher의 훌륭한 decision boundary 일텐데 (classification problem에서), 이는 곧 activation boundary 의 조합을 의미합니다. 그러므로 teacher의 knowledge를 가져오고 싶다면, activation 자체 보다는 activation boundary를 가져와야 한다는 흐름으로 이 논문에서 설명하고 있습니다.
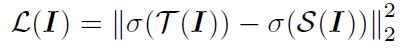
MSE를 사용하는 기존의 KD 기법 (Romero et al., 2015)
그 외의 다른 직관적인 설명도 있습니다. 기존 KD 기법들은 student network를 학습시키기 위해 teacher-student activation 간의 Mean-Squared Error (MSE)를 사용합니다. 다만, 이런 종류의 에러라는 것이 결국 strong response에만 초점이 맞춰지고, 실질적으로 decision boundary가 결정되는 weak response 혹은 zero response는 loss 함수에서 반영이 되지 않기 때문에 (SVM에서 다루죠?), Figure 1 에서 볼 수 있듯이 teacher의 decision boundary를 물려받기가 어렵게 됩니다.
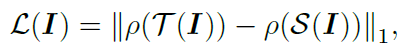
이 논문에서 제안한 activation transfer loss
반면에, boundary 자체를 학습하도록 loss를 주면 그런 문제가 없어지게 됩니다. 위의 식은 이 논문에서 제안한 것으로, teacher와 student의 activation 여부만 같아지도록 학습하는 activation transfer loss 입니다. p(.)는 neuron이 활성화 됐는지 (1), 되지 않았는지 (0) 알려주는 indicatior function 입니다. 문제는 이런 식의 indicatior function을 활용한 loss 함수는 미분이 불가능 하다는 점입니다. 이 논문에서는 loss 함수를 미분 가능하게 하기 위해 hinge loss 에서 아이디어를 가져왔습니다.
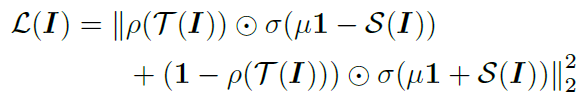
alternative loss
teacher network 가 활성화 됐다면 student network가 활성화 되지 않은 경우에만 loss 값이 생기고, teacher network 가 비활성화 되었다면 student network가 활성화된 경우에만 loss 값이 생기게 됩니다. s_i 에 대해서 직접 미분을 해보면 이해하기 조금 더 용이합니다. 논문에서 이 부분을 제공하고 있으니 읽어보시는 것을 추천합니다.