참고글 출처 https://littlefoxdiary.tistory.com/65
성능은 좋지만 무거운 BERT_large, 다이어트 시켜보자!
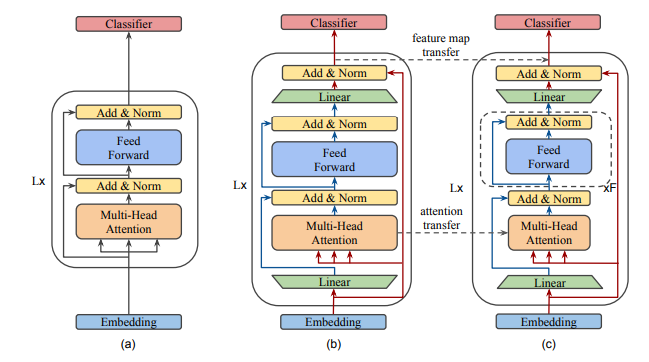
Bottleneck 구조 도입
Self attention과 FFN 사이의 밸런스를 맞춤
그 결과, 깊이는 BERT_large만큼 <깊지만>, 레이어는 <얇아진> 버전인 MobileBERT가 탄생
MobileBERT는 원래 모델과 마찬가지로 fine-tuning을 통해 어떠한 NLP 태스크에도 적용 가능하다.
성능 & 모델 사이즈 측면에서
- BERT_base보다 4.3배 작으면서 5.5배 빠른 모델을 확보
GLUE 태스크에서 BERT_base 모델 대비 성능 하락은 0.6에 불과
Pixel 4 모바일폰에서 63ms의 latency로 추론이 가능
SQuAD에 있어서는 심지어 BERT_base보다 높은 성적인 EM=79.2/F1=90.0 을 달성하였다
모델 개요