paper https://arxiv.org/pdf/1911.04252.pdf
글출처: https://hoya012.github.io/blog/Self-training-with-Noisy-Student-improves-ImageNet-classification-Review/
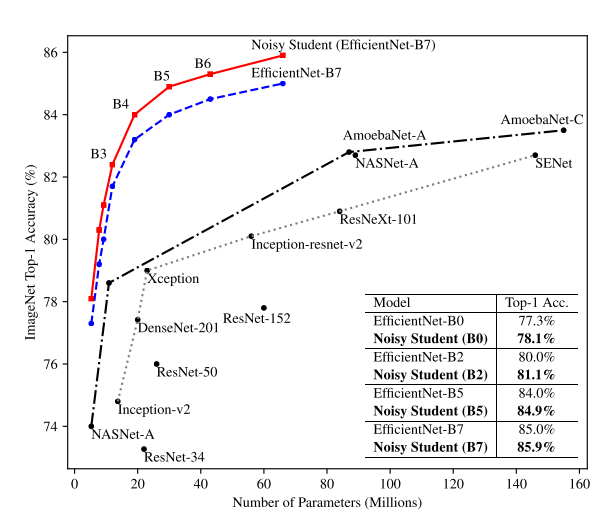
본 논문의 핵심 아이디어는 간단한 사진으로 정리가 가능합니다. 논문에는 알고리즘만 제시가 되어있는데, 설명을 돕기 위해 핵심 내용을 그림으로도 정리를 하였습니다.
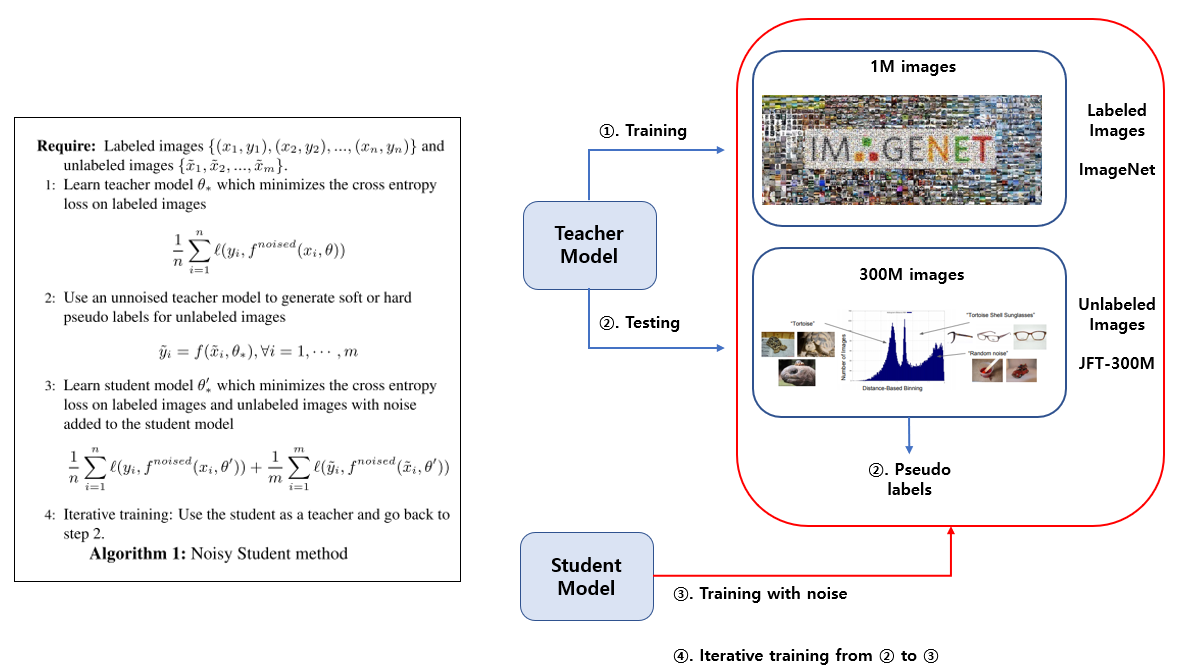
[Self-Training 알고리즘 & 그림]
우선 Labeled 데이터셋인 ImageNet을 이용하여 Teacher Model 을 학습을 시킵니다. 그 뒤 Unlabled 데이터셋인 JFT-300M을 Teacher Model 에 흘려 보내서 prediction 값을 구한 뒤 이를 pseudo label로 사용을 합니다. 이렇게 얻은 JFT-300M 데이터셋의 pseudo label과 기존에 사용하던 ImageNet의 label을 이용하여 Student Model 을 학습시킵니다. 이 때 Student Model에 noise를 주입하여 학습을 시킵니다. 이 과정을 반복하며 iterative 하게 학습을 시키면 알고리즘이 끝이 납니다.
Teacher – Student 구조를 보면 Knowledge Distillation를 떠올릴 수 있습니다. Knowledge Distillation은 Student Model을 작게(Compression) 만드는 것이 목표이고 Labeled 데이터셋만 사용하여 학습을 하는 부분이 이 논문과의 차이점입니다.
또한 논문에 제목에서도 언급했듯이 Self-Training 외에도 Noisy Student Model이 이 논문의 또 다른 핵심 아이디어입니다. Student Model을 학습시킬 때 “Stochastic Depth” , “Dropout” , “RandAugment” 등 Random한 학습 기법들을 사용하였고, 이러한 기법들을 Noise라 부르고 있습니다. 각각에 대한 방법론이 궁금하신 분들은 방법론을 누르시면 논문이 연결되니 참고하시면 좋을 것 같습니다.
RandAugment을 통해 바뀐 이미지가 기존 이미지와 같은 label인 사실을 student가 알게된다. 이를 통해 더 어려운 이미지도 예측을 잘 할 수 있게 된다. dropout과 stochastic depth인 경우 ensemble과 같은 효과를 내게한다. 다시말하면 강력한 ensemble 효과를 흉내 낸다고 한다.