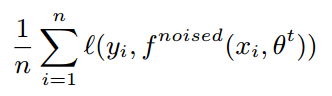(1) labeled image로 teacher model을 학습합니다.
(2) unlabeled image의 pseudo label을 생성하기 위해 teacher model을 사용합니다.
(3) labeled image와 pseudo labeled image를 결합하여 student model을 학습합니다. 학습된 student model을 teacher로 사용하여 pseudo label을 다시 생성합니다. 생성된 pseudo labeled image로 다른 student를 학습합니다. 위 과정을 반복하는 것이 Noisy Student Training 입니다. 참고로 student를 학습할 때는 dropout, stochastic depth, data augmentation과 같은 노이즈를 추가합니다.
Noisy Student Training은 self-training과 distilation을 향상시킵니다. **student는 teacher보다 적어도 동일하거나 더 큽니다. 노이즈와 pseudo labeled image가 추가되었기 때문입니다. 따라서 student는 teacher보다 더 나은 성능을 갖습니다.**이 방법은 정확도만 향상시킬 뿐만 아니라, robustness도 향상시킵니다. 저자는 ImageNet-A, C, P 에서도 test를 합니다. 아래는 결과 표 입니다.

Noisy Student Training의 알고리즘 입니다.

labeled image와 unlabeled image가 필요합니다.